It’s not always that I get seriously enthusiastic about a new and emerging technology. About 2 years ago (long before the VMware acquisition) I picked up this GPU virtualization technology, as it offers a new way of offering GPU acceleration to data scientists, developers, and researchers. VMware acquired Bitfusion just before VMworld 2019, which to me was one of the best announcements of last year. Today, vSphere Bitfusion has been announced with a release at the end of July. Now, let’s dive a bit in this technology, so you can see why I am this enthusiastic.
GPU Sharing
Sharing GPUs from a VDI-perspective is something we are doing for quite a while now, and perfectly makes sense because every session that is accelerated by a GPU, is also constantly using it (rendering, protocol encoding, video decoding within the session and sometimes for computational purposes). As soon as a user signs in (with non-persistent desktops), the GPU is allocated by the session and released as soon as the session is disconnected (with VMware Instant Clone technology, that is). This will ensure you are always using the GPUs you have in an environment in the most efficient way. Now, from a computation perspective, sharing is something completely different.
Use cases who use a GPU for compute purposes quite often would like to use a whole GPU, or at least all of it’s video memory. This is due to the nature of their work. Especially when talking about Machine Learning and Deep Learning tasks, the frameworks used (quite often PyTorch or TensorFlow), have native GPU support. They. will use the accelerator to load datasets in the video memory (which is a lot faster than RAM) and use the thousands of cores to run tasks in parallel on the data. As datasets can be quite large (especially with Deep Learning and image classification), the more video memory (or Frame Buffer) is required.
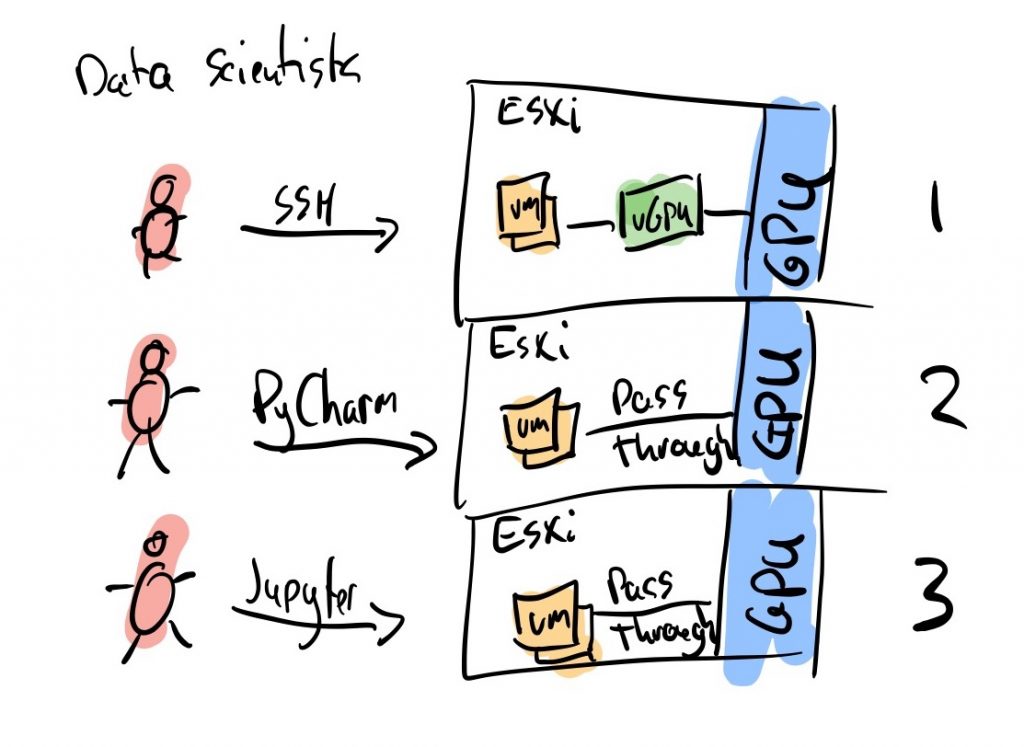
What I am seeing at customers. a developer or data scientist who uses a GPU doesn’t do that on a permanent basis. They have a VM running on a platform that has a vGPU profile or full GPU through passthrough assigned to it. In most cases, they connect to the VM through SSH or remotely through tools like PyCharm or Jupyter. If they aren’t sending CUDA (programmer language for GPU accelerated code) instruction to the GPU, the device is idle (which is most of the time). The GPU can’t be used by someone else, which might offer an issue when talking about scalability or TCO (total cost of ownership).

In the first use case (with vGPU) you are actually able to share the GPU by carving it up in vGPU profiles (NVIDIA Datacenter GPUs only), but quite often a data scientist needs the entire frame buffer, so they will most likely use vGPU only for mobility purposes (vMotion). In the second and third use cases, the full GPU is assigned to a single VM and most likely a single data scientist or developer. It might be able to share a VM, but I have never really seen that successfully happen.
Sharing on a per application or workload basis
Now, this is where vSphere Bitfusion comes into play. vSphere Bitfusion offers a way to virtualize a GPU and it does it on a per-application, session, script, or code basis. The VM in which the application is running, doesn’t have a (v)GPU installed, but just a vSphere Bitfusion agent called the FlexDirect agent. You can have as many of these VMs as you like, and none of them are directly attached or assigned to a (vGPU). This means that the hosts where the VMs are running on, also don’t have or need a GPU. Now to get accelerated, somewhere else in the network is a vSphere cluster with hosts that are equipped with GPUs, multiple of them. Those hosts run a Bitfusion appliance that has all the GPUs in the host passed through. The Bitfusion appliances have direct access to the GPU, without any scheduler between them.
In case someone who runs code inside the VM needs to send CUDA instructions over to a GPU, vSphere Bitfusion intercepts these API calls and sends them over from the VM to the Bitfusion Appliance through a low-latency network (RDMA or PVRMDA). The Bitfusion appliance runs the computational part and when ready, sends the result back to the FlexDirect agent, which in turn presents the result to the application.

How come it only virtualizes the computational tasks and not graphics?
vSphere Bitfusion uses the Flexdirect agent to intercept CUDA API calls. These calls are created from CUDA libraries which can be included in multiple programming languages (like C and Python). As the CUDA framework is specifically created to execute computational code, no other API can be utilized to offload through Bitfusion. No other API is currently supported (like OpenCL for computational tasks, or OpenGL and DirectX for graphics).
What does the flow look like?
Like mentioned above, vSphere Bitfusion intercepts CUDA instructions. Certain API calls have been exposed so the Flexdirect agent is able to detect when an instruction is created and knows when to intervene. “Virtualizing” these computational tasks works a bit different than virtualizing CPU instructions. The main reason is that these CUDA calls are made from a user context instead of a system context. The CUDA framework lives in the user space of a linux distribution, so virtualizing that part of the stack is in this case enough.

In the above diagram, you can see the actual flow of an application which is accelerated by GPUs through the use of vSphere Bitfusion. In the VM in the left host you can see a PyTorch application (in yellow).
The PyTorch app calls the CUDA framework to accelerate the code through GPUs. The CUDA instructions are being intercepted by the FlexDirect agent and sent over the network tot the Bitfusion Appliance. The Bitfusion Appliance also has the CUDA framework running and reaches out to multiple GPUs which are passed through to the appliance. The Bitfusion Appliance also has the NVIDIA drivers installed so it is able to talk to the GPUs.
After the GPU job is finished, the result will be sent back over the network to the FlexDirect agent, which in turn will present the outcome to the CUDA framework and eventually to the PyTorch application. It’s essential that a low-latency network is used between the VM and Bitfusion Appliance as the application in the VM doesn’t know the GPU is somewhere else on the network and doesn’t expect any latency. So, any extensive latency (>0.005 MS) might generate time outs in the application. In general, Melanox and Intel (next to other vendors) have multiple types of NICs available that are capable of staying within the latency limits and are fully supported with VMware vSphere. Another thing to keep in mind is that a passed through GPU is only supported at this time. Using vGPU (Virtual GPU) doesn’t make sense because it will only create more overhead in scheduling the GPU jobs.
Does it work with containers as well?
This is where I believe the beauty and potential of the platform stands out. Running a non-persistent workload (so, not directly tied to a user-created VM) is a perfect use case for vSphere Bitfusion. If you are able to dynamically assign a GPU to a containerized application, but only at the moment the application requires it, you are simply getting the most out of the GPUs. vSphere Bitfusion can do that, which is the most important reasons why I think combing vSphere with Kubernetes with vSphere Bitfusion as the base infrastructure and putting the Pivotal stack on top of it, creates the datascience/developer platform of the future. A developer or data scientist doesn’t have to worry anymore about getting the right number of GPUs or any GPU for that matter. The platform will automatically assign them and will release them when the application or workload is finished.
The next recorded demo shows how a containerized application (in this case a PyTorch application), can be accelerated through the use of VMware vSphere Bitfusion including an overview of everything happening inside the vCenter Webclient.
If you like to know how to build your own AI stack, check out my Mastering Voodoo Series.
It’s awesome and I want it, where can I get it?
The solution has been announced today, but is not publicly available yet. That is likely to happen in this quarter (VMware financial quarter), so expect it somewhere in July. If you like to know more about this technology, there are a couple of links I would like to share:
VMware Announcement Post:
https://blogs.vmware.com/vsphere/2020/06/vsphere-bitfusion-elastic-infrastructure-ai-ml.html
The acquisition article:
https://blogs.vmware.com/vsphere/2019/07/vmware-to-acquire-bitfusion.html
The Hardware Accelerator Page: https://www.vmware.com/solutions/business-critical-apps/hardwareaccelerators-virtualization.html
The Blog Series on GPUs on vSphere https://blogs.vmware.com/apps/2018/07/using-gpus-with-virtual-machines-on-vsphere-part-1-overview.html
The post Announcing vSphere Bitfusion as GPU acceleration platform appeared first on vHojan.nl.
The original article was posted on: vhojan.nl







